�������ߣ�010-66095089/13521200337



�������������۲ű���2026���´�ҵ���� ��Ŀ����


GMIC Beijing 2018 ����һ�죬���ݽ����� Facebook ��ϯ AI ��ѧ�� Yann LeCun���������˹������ѧϰ�������о��ɹ���ͬʱҲ���������ѧϰ��δ�����Լ�����������Ҫ���ٵĵ���ս��

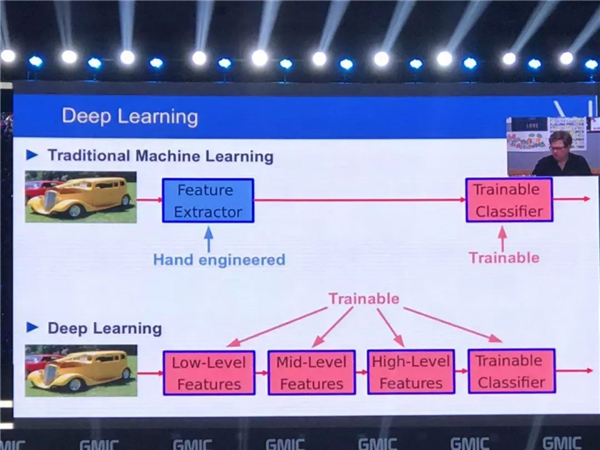
���ලѧϰ�����
���� AI ϵͳ����ʹ�õļලѧϰ�����е� AI Ӧ�ã�������ͼ��ʶ������ʶ��������ʶ�𣬻���������ȵȣ���Щ���Ǽලѧϰ��Ӧ�á�ѵ���ලѧϰģ����Ҫ����չʾ�������ӣ�����������ȷ�𰸣���������û���ѧ�Ὣ�����ͷɻ����ֿ��������������չʾһ������ͼ����˵�ⲻ��һ������Ȼ������ԶԲ������е������´��������չʾͬһ��ͼ��Ļ�����ͻ�õ��ӽ���ȷ�Ĵ𰸡�
���ǿ��ԶԻ������ж˵��˵�ѵ����������ض�������feeding ԭʼ�� inputs���ͻ��Զ����� outputs������ѧϰ�������Ĺ����Ƕ˵��˵�ѧϰ���̡�ͨ�����ַ�ʽ������������ܸ��õ��˽�������硣

����������磬ʵ��������뷨�ǿ��Ի��ݵ��ϸ����Ͱ�ʮ���������ʶ��ͼ��ͬʱҲ�кܶ�������Ӧ�ã�����˵�����������Դ���������ʶ��������ܶ��Ӧ�á�����֪�������������Ƿdz���ģ�ֻ���ڷdz�ǿ��ļ�����ϲſ������ã���Ҫ�� GPU ���Ը�����

�����ѧϰ��ñȽ��ձ�֮ǰ����������Ҫȷ��������һЩϵͳ����������Щ���������һ�������������� 2009 �ꡢ2010 ����ŦԼ��ѧ������һ��ʵ�飬���Կ���������ʶ����·�ϵĽ���������Լ�·�ϵij����˵ȵȣ�����ڵ�ʱ��û�б���Ϊ��õ�ϵͳ���ٹ�����֮��Խ��Խ�����������ѧϰ�ǿ�����Ч�ģ����Է������õġ�

�������ҿ��Կ��������統��ʹ�õļ����㣬����˵�� 100 ����� 180 ���һЩ�˹������磬�� Facebook �������Ǿͻ�㷺ʹ�á��������ҿ��Կ������������ڲ����½��ģ��е�ʱ����ֵ�����Ҫ���˻�Ҫ�á��������ܷdz��ã��Ѿ���Ϊ��һ�ֱ�ˡ�
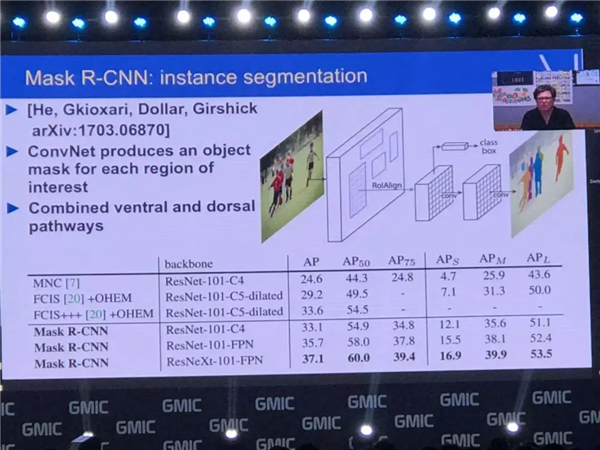
���� Facebook �˹����ܲ����������о������� Mask R-CNN�����Կ������Ľ���������Ա��������ͼ�����ҸղŸ����չʾ�����ӣ�չʾ���dz��õ����ܡ�������������ʶ���ÿ���ˣ�ͬʱ����Ϊÿ���˼�һ����ǣ����Կ��Ժ��������ֳ���һ���˻���һֻ����

�������ҿ��Կ������ϵͳ����ʶ����ԡ��Ʊ����ˡ����ӣ�Ҳ���������������ж��٣�����Ҳ����ʶ�����·���������������֮ǰ��ϵͳ��Щ����Ļ������ǵ�ʱ������Ϊ��Ҫ 10-20 ��ʱ����ܴﵽ������ֵ�Ч����

��Ҳ�� Facebook ������һЩ�о������� Detectron����ҿ�����������Ĵ��룬������̽�� 200 ���ֲ�ͬ�������Ҳ�� Facebook �� AI �����һЩ�о������Dz�����������һЩ���ģ�ͬʱ������Ҳ�����������ˣ������Ļ�������ض����Ը��õ���֪���ּ�����
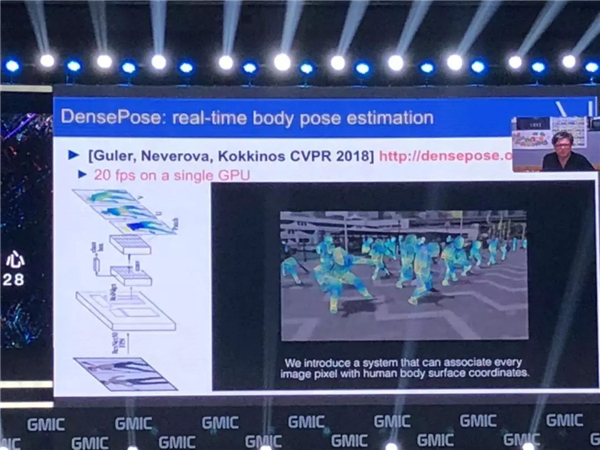
��Ȼ�����������ܶ���Ŀ���� Facebook �������� DensePose �����ļ�����Ԥ���������Ϊ������������һ��ϵͳ�ܹ�ʵʱ�����У���һ����һ�� GPU �����С������Ը��ٺܶ��˵���Ϊ��������Ƶ���dz���ȷ������ʵʱ������һЩ��Ӧ�����ݺ���Ϣ��������Ӧ�Ĵ���Ҳ�ǿ����õģ���Щ����һЩ���µ�Ӧ�á�
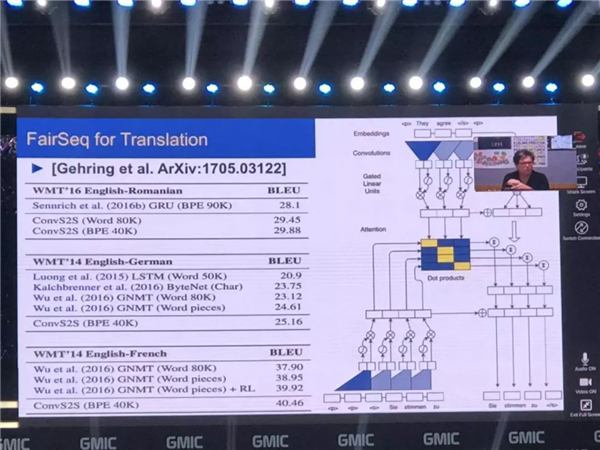
��Ȼ���õ������ļ������������Խ���ʶ��ͼ���沿ʶ��Ҳ����ʶ���˵��ж���Ҳ�����������룬���� Facebook �ڼ����������о���FairSeq�������ǿ��������ϵͳ�����з���Ĺ�����
�Ҿ��ö�����ҵ˵���������Ŀ����о����ǻ���һ���dz����õĹ��̣�ͬʱ����Ҳϣ���Լ��������ļ����ܹ����������������������������Ȥ�����⡣������Ϊ AI ��������������ǽ�����⣬ͬʱ����������ǽ���ܶ������Լ����������ս���������ǻ����ѧ�Ŷ�һ���ⷽ��Ŭ����

�������ڹ�ȥ�ļ����FAIR ��������һЩ��Դ��Ŀ�����������ѧϰ���磬�������ѧϰ��ܵȵȡ�

�ҸղŽ���ÿ�춼����һЩ�µ�Ӧ�÷����������ѧϰ�Ĺ㷺Ӧ��Ҳ��һ���ƶ���ѧ������о����ڽ��������������ѧϰ�ᷢ������ĸ�����
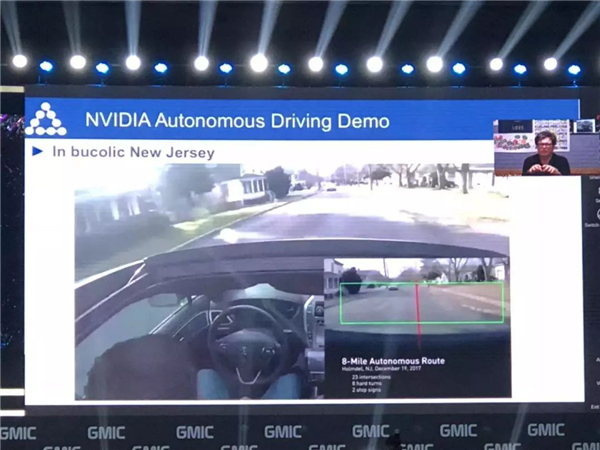
������Ϊ��Ҿ�һ�����ӣ������Ƶ���ֳ�������һ�ּ��ٹ��̣�������ѵ����ȥ���м�ʻ�����ҿ��Ե������ֵķ������������ó��Լ�ȥ���м�ʻ��������Ҫ����ȥ����У����

�����ֱ��
����������������һ�¿��ֱ�̣������̿������˹���������͡�
����ע������Ա��д���룬���߽�д������ high-level �Ĵ��룬�����ṩ������������ X ���Ӧ������ Y �����ӡ�����������ṩ�����ݼ����Զ�ѧ������������X������������ Y ��ӳ�䣨�������������߽�ϳ���Ա�ṩ�� high-level �Ĵ��룬����������Ϊ�м亯������ȫ�õ���������
��Դ��֪��@������
��https://www.zhihu.com/question/265173352/answer/291994649��
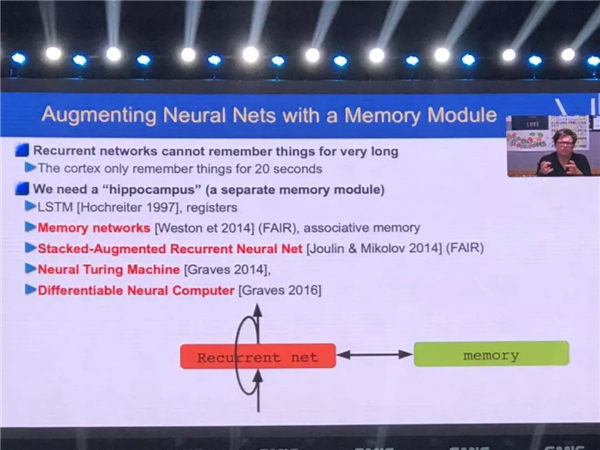
����ͨ���о�����ʵ��������һ�ֱ�̣���������������ϵͳ������ѵϵͳ�������ijһ�����������

���Ǽ���ǰ����չ�Ĺ��������� Facebook ��ŦԼ��ѧһ�����������Ŀ�������Ŀ��ѵ��ģ�ͣ������ܹ��ش���ص����⡣����Ȼ���Դ��������У�Ҳ���Կ����˹��������Ƕ�̬�ģ��ڲ��ϱ仯�ġ�

��������һ�����ӣ������Ҫ����һ���ܹ��ش��������ϵͳ������˵����ͼ��ĸ�������ȡ�Ϊ�˻ش����ͼƬ�Dz����и����������״��֮�����Ǿͻ���ϵͳ�����м��㡣����˵�����ж����Ƿ����壬�����ж�����ɫ�������������Ĵ���ʲô��ͨ����ô�����ǿ��Խ�����һ���˵��˵Ľ���;��������Ҳ��������������µ����⡣��������������ݲ�ͬ�����������仯��

��ҿ�����������������������õ���һЩ���ѧϰ���µijɾͣ�֮����������һ�¹��� AI ��û�����Ǵ������ġ�

������ѧϰ��Ҫ��ʶ
�����¼������Ҿ��ÿ��Խ��뵽�������������и����Ӱ���������һ���̶��ϣ����Ǿ��û�������ȷʵӵ��һ�����˹����ܣ�������ϸ���ϣ����ǻ���Ҫ���и���̽�֡�
�����ڻ���ѧϰ���棬������ô���أ���������Կ�����һЩ�����ͼ��������Щ�µķ�������ʵ�ʵ��������ʵ���ַ�ʽ��̫�ɹ�����Ϊ�������ѧϰ��������Ҫ����������ھ���Ϊ���ڻ������������в�ͬ�Ľ��������������ʵ���������Dz��ܹ�ȥʵʩ�ġ�

��ʱ���û���ѧϰ�ܳ�ʱ���������Ϸ�������ں��Ĺ��ܷ��棬����ȷʵ��û�д�����������Щ�������������ģ�ֻ�����ǻ�û���ھ����������Ҳ���ԶԻ����������и������ѵ������������Ҫ��ϵͳ���г�ǧ����ε�ѵ��֮�����Dz��ܹ�����ѧϰ��
��Щѧϰ��������ѧ��صģ�������ʵ�ʵ�����в�����ʵʱ���У���������ֻ�ܹ�����ģ�⣬����Ҳ��Ҫ���ǽ��кܶ�ij��Բ��ܹ��û���ѧ����

Ӥ��������ôѧϰ���أ�����������½����ͼ��������չʾ�ģ����������µ�Ӥ�����ܲ�̫�˽������˶����ɵ��������˰˸���֮�������Ѿ�֪������������������ˡ�
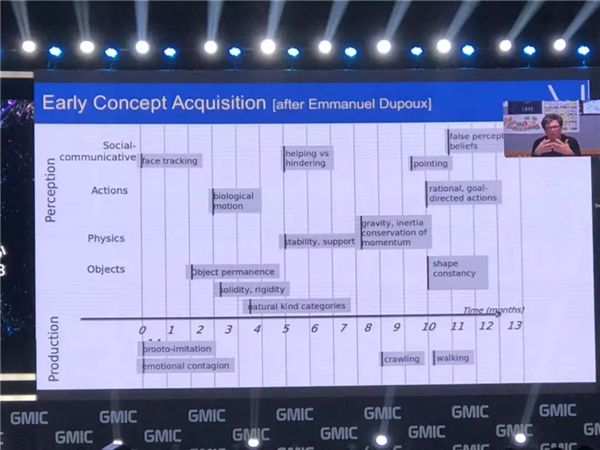
���������½ǵ����СŮ���dz��˲����ҵ�һλ������������չʾ��Ӥ����ôѧ��һЩ�����������Ҳ�ܹ��˽�һЩ�����������ԭ�����������������������ѧ����һЩ�������ƾ�����dz�ʶ��õģ�Ӥ������ѧ����Ǿ���һЩ��ʶ��
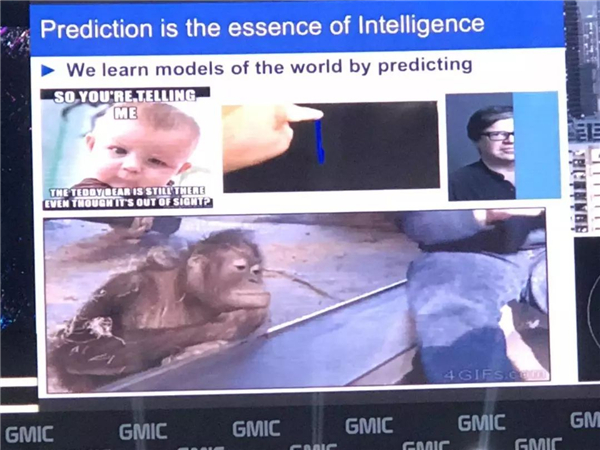
������������չʾ�������龰�������ҿ�һ����������ɣ������������ʱ������ѵԱ�����ǽ���չʾһЩ���������Դ��������������ħ����Ц�����������ǻ��������������ԭ�͡�

������ϣ�������ܹ�����һЩ������ʹ��ϵͳ���У����ջ������ܽ���һЩԤ�⣬����һ����Ч���С������������ļල����ѧϰ���ܹ�ʹ�û����õ�ѵ���滮��������������Ҫ������һ��ϵͳ��

�����´εı�����������Ҿ�������Ӧ�������Ҽල�����ලѧϰ�������������ı�ﵱ��Ҳ�����һЩ��ʶ�Ե�ѧϰ��

���ܽ�һ�£����������������һЩ�dz�����������飬����һЩԤ���Ե�ģ�ͣ����ɻ������й滮���������ǵij��Խ���Ԥ�⡣
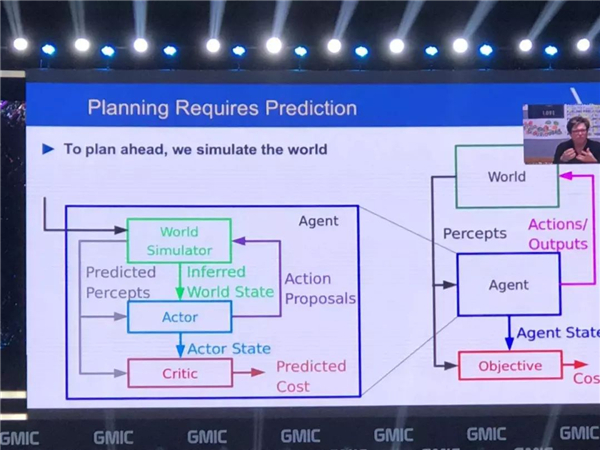
���ǽ����˶Կ���ѵ��������˵���ǿ���ѵ���������˽��ĸ������Ǹ����ܵģ�������ʵ�������л����ʲô���Ľ�������ڷ����Ŀ�������Ҳ��������Ԥ�⣬�����е�ʱ���еĽ������ٵģ�������ʵ�ġ�ͨ����ô�����Ǿ��ܹ��õ���ͬ���������Ľ����֮��õ��˺ܶ��Ӱ���ͼƬ��

���ǵ�ϵͳ�ڽ���ѵ��֮��������һϵ�е���������ҿ�����Щ���˵���ף�������һЩ�Ǽٵ�ͼ�����ɻ������ɵģ�������������ʵ�ġ�
���ǽ������ܻ���������չʾ���µĽ�����õ��ijɹ��dz��á���֮������ϣ�����������֮���ܹ����뵽���ǵĻ���ѧϰ���С�

���������һ���ܽᣬ�Ҿ��üලѧϰ�Dz��ܹ�������ģ��������ලѧϰ����������ѧϰ��ʽ�����ܹ������������Ѿ������˺ܶ��˵���Ȥ������ҲҪ���и��ೢ�ԡ�����һ������Ҫǿ�����ǣ�����Ҫ�û����ܹ����������������ѧϰ�ܴ�������ʲô��������������ͬʱҲҪ�˽���AIʱ�������������������ж�ߣ������ж�ǿ��
����������ҲҪ�����ſ��ֱ�̵�����ѧϰ�ķ��������չ�������Ҫ����������Կ���ѵ�����о�����Ȼ��������ָ�����й����ѧϰ�ı�����һЩ��������չ�����Ǹ��ӵļܹ������������Ҳ����ָ�������ۡ�

���ڼ����ල�����ƺ���Ȼ�Dz��ϵ������������ල����ʧ����ͻᵼ�³���һЩ�����۵IJ��������������ԣ�������һЩ�µIJ����ı���������֮��Ӧ���ж�ά�ȵĿ����ԡ����ܻ����һЩ�¿�ܣ�������һЩ��̬Ӱ�����ǻ������������ѷ����и������������Ҳ��Ͻ��п�Դ��
��Ȼ���������ǵĹ������ܴ��ǹ������ǵ��ƶ����ߺ���������Խ��Խ�����ˣ�Facebook ���û�����ÿ���ܹ��Ƴ���� 20 ���Ų�ͬ��Ӱ����������ϣ���ܳ�ַ����ⷽ�����������������һ�ֺ�ǿ�������������⣬����ҲҪ����ǿ��Ӳ������ʹ�û������ܹ��õ�רҵ���Ĵ�����
|

