服务热线:010-66095089/13521200337



大赛报名|“雄才杯”2026创新创业大赛 项目征集

CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,香港中文大学(深圳)、雷锋网联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办。
从 2016 年的学产结合,2017 年的产业落地,2018 年的垂直细分,2019 年的人工智能 40 周年,峰会一直致力于打造国内人工智能和机器人领域规模最大、规格最高、跨界最广的学术、工业和投资平台。
高文教授介绍,城市大脑1.0是一个以云计算为核心的系统,由于系统各部分之间没有很好的分工协调机制,使得系统成本高、响应速度慢、数据的可利用性低。
在他看来,城市大脑2.0是一个端边云分工协调的混合系统架构,可以有效解决城市大脑1.0的大部分问题。
城市大脑2.0的核心在于数字视网膜及其标准化,它相较城市大脑1.0具备四大方面的性能提升:
1、它有先进视频编码技术:节省存储和带宽50%以上;
2、它可以定制ASIC边缘计算:节省云计算资源90%以上;
3、它能在原始图像上特征提取:低延时和高精度;
4、它还可以做标准化特征的提取,存储和复用:显著提升信息密度和价值。
以下是高文院士线上演讲的精彩内容,雷锋网作了不改变原意的整理与编辑:
今天我与大家分享的演讲主题叫做“城市大脑2.0,边端云合理分工的人工智能赋能系统”。
先谈谈第一个话题:城市大脑1.0。
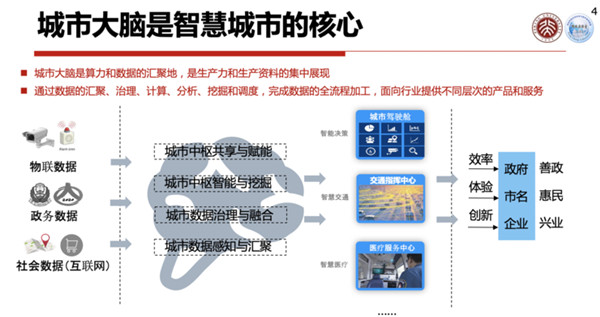
城市大脑是现有智慧城市中的一个核心系统,它将算力及数据汇聚到一起,加上算法就可能产生出非常好的结果。
譬如,基于互联网的数据、政务的数据、社会的数据,把它们集中到一起,提供一个云计算服务,就可以提升政府效率、加速企业创新。
智慧城市系统之中,汇集了各类各样的数据,其中有90%左右的数据都与图像、视频相关联,如何处理好图像和视频数据,在城市大脑系统中是非常关键的要素。
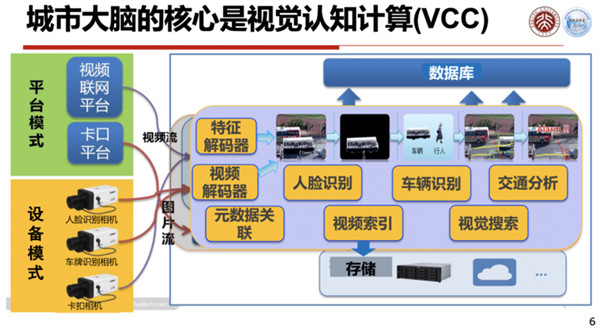
现有的系统中,数据基本以图像与视频两种形式进入:
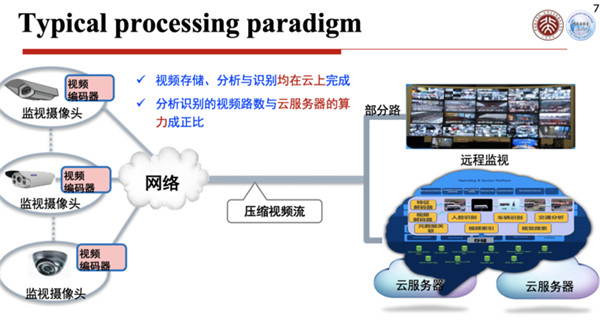
第一种模式:摄像头就是一个简单的传感器,捕捉到图像或者视频以后,进行一个编码压缩,传送给云端,云端将它存储起来。
也可能将它解码之后进行分析,识别出人脸、车辆,或者进行交通数据的分析等等,这是一种信息或者数据感知的模式。
另一种模式叫做智能终端,在摄像头这一端就把人脸或者车牌等信息识别出来,识别出来的信息被传送到云端,直接可以进行分析使用。
这两种模式是目前城市大脑中数据使用的主要模式,当然这两种模式都多多少少存在一些问题。
如果仅仅作为一个感知终端,后面如果需要调用,除了解码以外,还要进行特征提取等工作,需要大量的计算程序,这些计算非常耗费云计算算力资源。另外,智能终端还无法识别出未被指定的人或物。
所以,我们我们需要一个更好的系统,这个系统不仅云上算力资源需求不多且可以完成一些未经规定的动作。
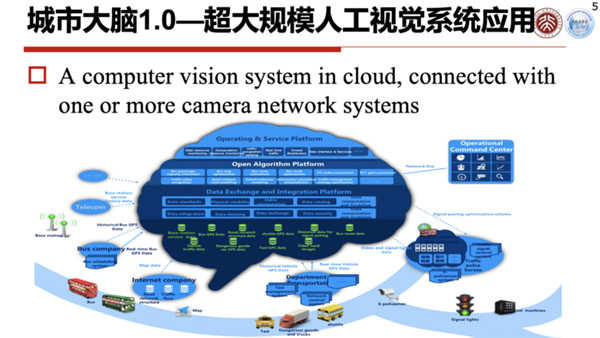
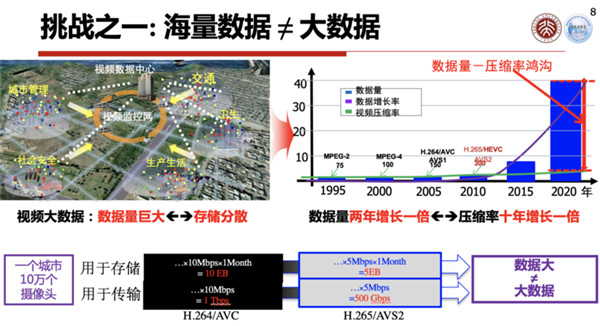
现在的城市大脑1.0,它是一个具有海量数据的系统,但是这个海量数据并不等于大数据,因为90%的海量数据都是没有结构化的,只是进行了一个简单的编码压缩。
另外,这些数据的价值也比较低,它不是结构化的,你无法在上面进行分析,这也是为什么很多智慧城市的视频数据,一段时间之后就被覆盖了。
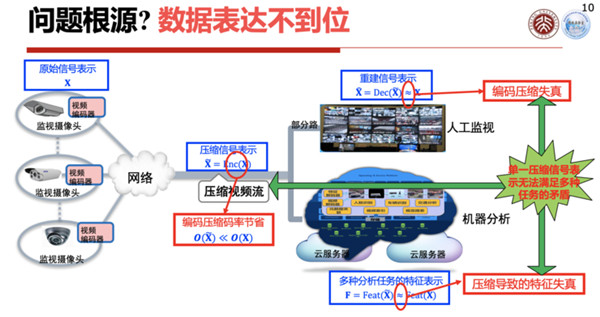
怎么才能改变这个现状呢?其实问题的实质就是现有的城市大脑里的数据表达是不到位的。
为什么不到位呢?如果你只是感知数据后,将编码压缩送到云端,它还是一个非结构化的数据;如果你把它识别出来是张三、李四,或者车牌号多少,虽然它已经结构化了,但是它是过度结构化的,对于没有规定的任务就无法执行了。
所以我们需要一种泛化能力更强的数据表达,这个数据的表达是一个机缘表达,用这些机缘既可以完成现有的任务,也可以完成现在还没有定义的一些任务。
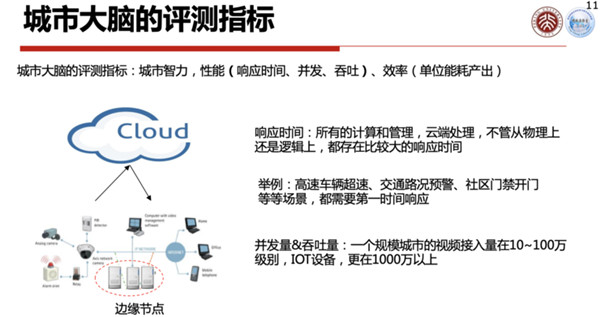
当然这些数据表达想要得到一个比较好的结果,整个系统就必须做得好。所以我们现在考虑城市大脑应该有一套评测的指标,包括系统的智力、性能(响应时间、并发、吞吐)、效率(耗电多大)等等。
如果某套系统可以通过评测,那就代表这套系统比较智能化了。
城市大脑1.0系统的弊端在于:它的智能代价比较高,要么是造价高、要么就是耗电高。
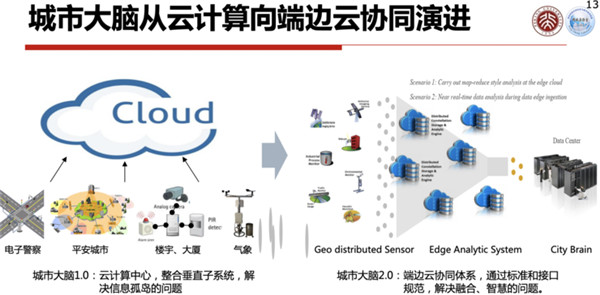
我们希望城市大脑变得更智能,或者效率更高,怎么办呢?我们希望把现有的城市大脑1.0升级到2.0。
一个可能的做法就是要合理分工,我们把原来的传感网络和云合并的机器变成边端云协同的机器,云上只需要配备最低的算力,一部分计算放置于边缘,一部分计算分配给终端,这样组合起来使得整个系统最优化。
系统到底应该怎么升级,或者这个结构做成什么样比较好,我们先来看看人的视觉系统是怎么运行的。
人的视觉系统是非常合理的、能效比非常高的系统。比如说我们每天只消耗相当于20瓦电灯泡的能耗就能做很多的事情。
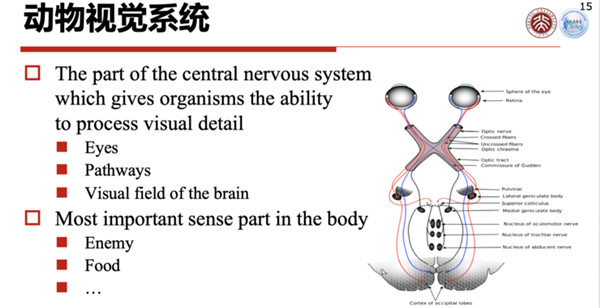
人的视觉系统为何可以做到如此的低功耗、高效率?人的视觉系统主要由三部分组成,包括眼睛、视觉通路和大脑的视觉眼,这三部分分工非常严密。
比如说大脑有了一个刺激信号,通过神经通路传到大脑不同的视觉眼,不同的视觉眼分工做不同的响应,就可以完成很多事情,比如说感知、决策等。
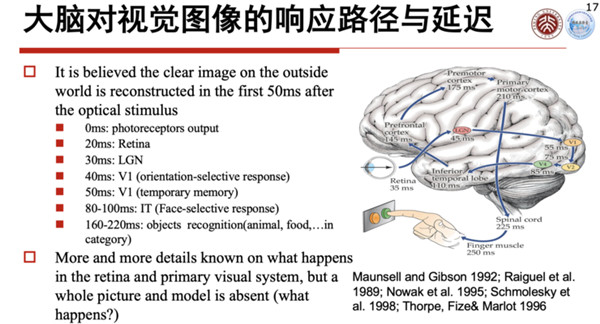
不同的感知路径或者不同任务的复杂度,其实人的响应度是不一样的。(见PPT)这是1992年一张研究的示意图,你可以看到当你给一个人下了一个指令说“你给我按一下绿色按钮”,这个执行是需要经过一定延迟的,比如说视网膜有35毫秒的延迟,从视网膜到下一个环节又有30毫秒的延迟,最后到了肌肉、手指头动作下去,大概有250毫秒的延迟,这个延迟就告诉我们,对不同的任务,我们整个视觉通道和脑的处理分工是非常严密的,使得简单的任务可以响应很快,复杂的任务响应很慢,分工合作,这样的系统就能做到能量最优化。
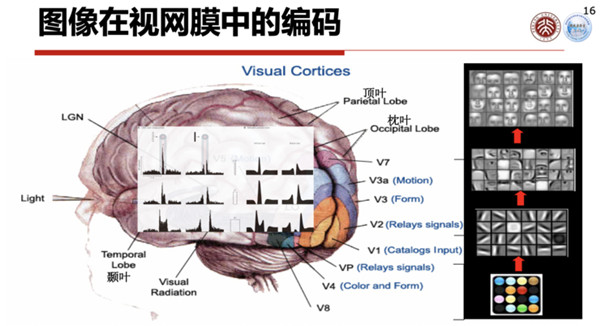
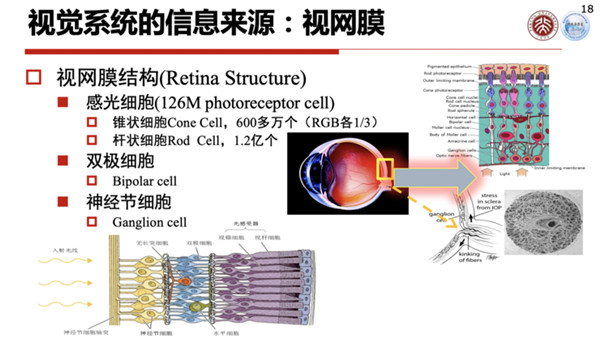
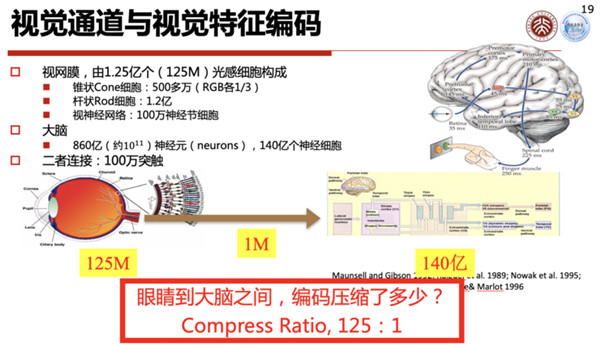
视觉系统最前端是视网膜,它的结构是由感光细胞、双极细胞和神经节细胞三类细胞组成的。
数字视网膜里面,大概有1.2亿到1.26亿个感光细胞,其中有锥状细胞核杆状细胞,锥状细胞有600多万个,杆状细胞有1.2亿个,它们可以感知光线的强弱等等。
这些感光细胞通过双极细胞,最后汇聚到神经节细胞,进到神经纤维、视觉通道,通过大脑进行传输。
神经节细胞的数量只有差不多100万个,换句话说从视网膜到视神经,它已经有一个差不多125:1的减缩,这个减缩我们可以把它理解成视觉信号的压缩,或者特征压缩。
所以我们在视网膜和大脑之间已经有一个压缩,这个压缩应该说对整个大脑有效的工作其实是起到非常关键作用的。
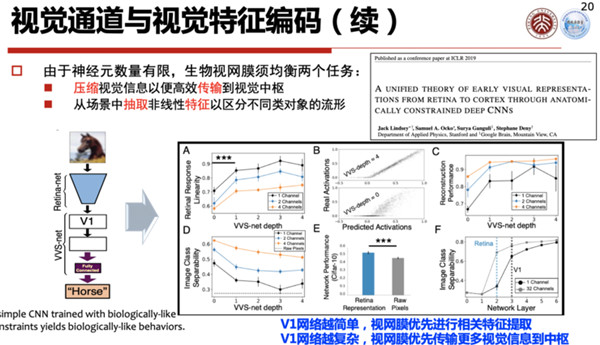
当然它不仅仅是一个压缩,它和后面的感知是紧密相关的,比如根据你任务的简单和复杂程度,它们提取的视觉特征也不一样,简单的任务就会优先采取相关的策略,复杂的任务,它就把相关的信息往后传。
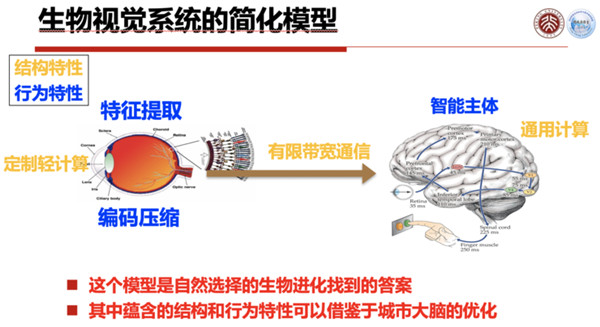
一个生物识别系统的简化模型,从视网膜到大脑,信息进来以后经过一个特征的编码压缩,特征提取出来以后向后传输,传到智能主体(脑),所以在视网膜这一端是一个定制的轻量级的计算,通过视神经这样一个有限带宽的通信送到智能体。
这样一个简化模型,对视觉通道是有很大作用的,所以大脑上有一个通用计算,这里我们可以把它整个特征的类别分为结构特征和行为特征,这个模型是经过自然进化,最后产生出这样一个优胜劣汰找到的答案。
这个答案告诉我们仿生视网膜的架构,它有非常好的能量优化的特点,这个特点可以给我们提供一个很好的借鉴,如果我们想把整个城市大脑也做得能量优化或者能量高效化,就可以按照这样的构造来进行结构。
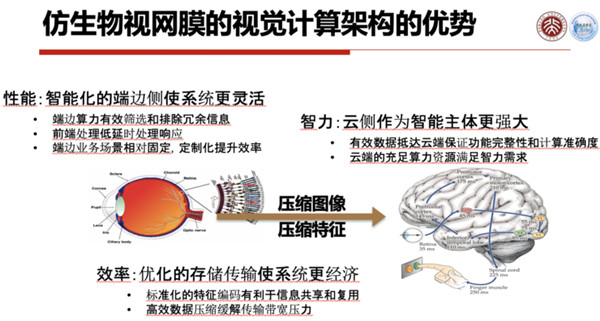
所以从视网膜传到大脑之间,它是一个特征压缩,我们叫做特征编码,当然这个编码和现在传统的图像编码并不一样,它是一个特征压缩编码的东西送到大脑中去。
另外,现在我们城市大脑里面不能仅传特征,也要传压缩图像,因为有的时候我们还需要用人眼去确认一些东西,所以压缩图像也还是要传的,这就使得我们现在城市大脑里的架构和真人的视觉系统并不完全一样,我们是两个综合或者绑定的系统。
有了这样一个借鉴,下面我们就看城市大脑2.0到底应该怎么样来设计。
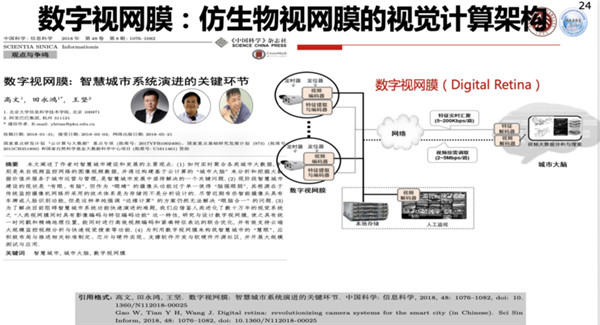
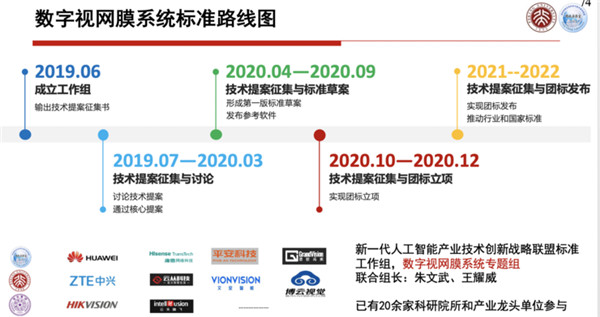
很显然它必须是一个边、端、云合理分工的系统,这个系统我们经过了一段时间思索以后,2018年我们就投出一篇论文,这篇论文最后是在2018年5月份网络出版,最后正式是在2018年8月份在《中国科学》上发表,我们把边、端、云结合的最核心的技术叫做数字视网膜,它是整个城市大脑2.0里面一个基本架构,我们把它叫做仿生视网膜的计算架构。
数字视网膜现在形成了有8个特征的定义,这8个特征原则上分成三大组。
第一组特征的定义是和时空有关的,一个数字视网膜的终端必须要有全局统一的时空ID,包括全网统一的时间和精确的地理位置,比如说GPS或者北斗的位置,有了这个东西之后,城市大脑就很容易同步,或者很容易可以对标。
第二组特征简单来说是视频编码+特征编码+联合优化,这是所有的摄像头都应该支持的一个工作,当前绝大部分摄像头只支持视频编码。
视频编码很容易理解,就是为了存储和离线观看影像重构。
特征编码是为了模式识别和场景理解的紧凑特征表达,联合优化是因为现在在城市大脑里面它有两个码流,一个是视频编码压缩流,一个是特征编码压缩流,这两个码流会捆绑到一起进行传输,所以我们要有一个优化策略,把这个带宽到底分多少给视频编码、分多少给特征编码,这样通过一个联合优化,使得整个系统是最优的。
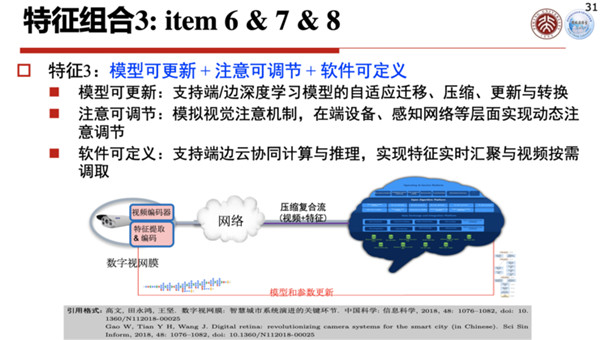
第三组特征,简单来说就是模型可更新、注意可调节、软件可定义。
什么叫模型可更新呢?因为我们现在必须要考虑怎么样支持神经元网络,不同的模型升级了,你要可以实时更新。
注意可调整是说,现在的摄像头是没有注意的,你把这个东西指到哪儿,景深设定到哪儿,它就在那儿,当然可以通过人工远程调节它,可以拉近、拉远等等,但是它不是自动的,我们希望它能做到自动的注意可调节。
最后一个特征就是软件可定义,这一点大家很容易理解,系统要想升级,可以通过软件定义的方法,对系统自动升级。这三个特点如果具备,终端就可以做得非常智能。
当然,要想把数字视网膜技术全部用起来,这里面有一些使能技术。
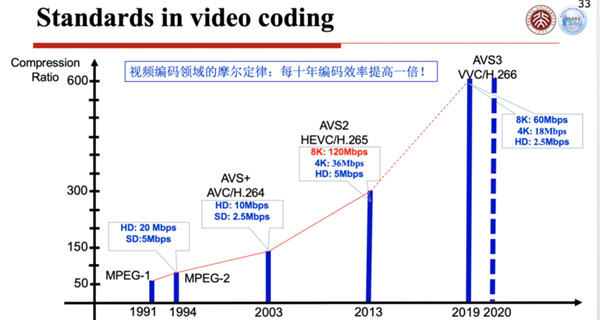
第一个是视频编码,现在做城市大脑、监控系统都离不开视频编码,摄像头里面都有一个视频编码芯片,视频编码芯片用的标准,最早期是H.264,或者用AVS的编码标准,最近开始使用H.265或者AVS2的标准,未来不久就会用上H.266和AVS3的标准,这个标准差不多每10年就会更新一代,效率每10年就会提高一倍。
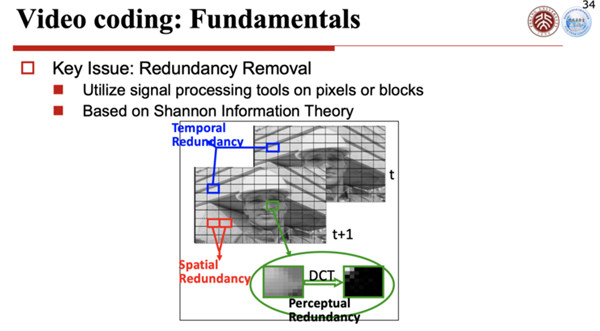
为什么能够做到编码压缩?一个视频是一个图像序列,图像序列里面包含了很多数据的冗余,基本上有三大类冗余:一类是和空间冗余有关的,一类是和时间冗余有关的,另外一类是和编码冗余有关的。
所以现在整个视频编码里面用的算法,我们一般把它叫做混合视频编码架构,这个混合就把刚才三种主流的冗余用不同的算法去掉。
比如说为了去除空间冗余,一般我们采用正交变换,比如说DCP变换等等正交变换把它去除掉。为了去除时间上的冗余,就是帧和帧上的冗余,一般我们会采取预测编码,比如说各种各样的滤波器,把帧间的冗余去除掉。
为了使得编码的分配最符合熵的定义,我们使用信息熵编码来去除编码上的冗余,这三个冗余都去除干净了,整个视频流里就可以压得很小,只有有用的信息、有用的数据甩出去,这些冗余都被挤压掉了,这是视频编码。
要想把视频编码做得好,算法要做得很精,随着时间的推移,我们可以用计算、带宽把这些东西一点点都去除掉。
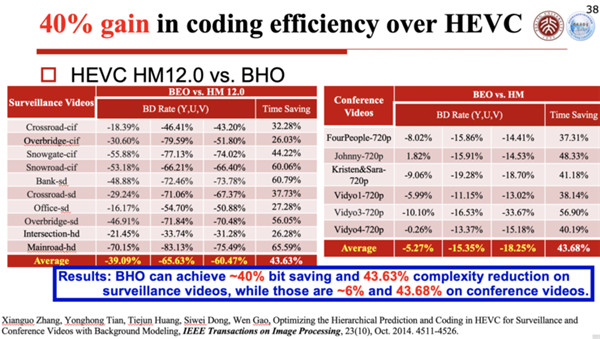
当然,这些年我们除了不停地优化算法之外,我们还提出了一种背景建模的技术,使得编码效率在原有的技术上又可以提高一倍。
这里有很详细的一些数据测试作为依据,而且这些东西都已经发表论文,比如2014年我们在TIP发表了一篇论文,里面有这样一些研究结果。
AVS2在2016年已经成为我国的标准,同时它也是IEEE1857标准的第四部分。现在我们做AVS3的时候,就是IEEE1857的第10部分。
AVS标准是在2019年3月份第一版就发布了,H.266一直到今年7月份第一版才发布,我们超前了H.266有一年三个月,这是有史以来第一次。
AVS3这个标准去年3月份第一版发布以后,去年9月份海思就把芯片做出来了,在阿姆斯特丹的一次广电展上,这款芯片一经面市,引起了很大的轰动。
它可以支持AVS3、8K解码,是120帧的,这个芯片现在已经装配在很多4K、8K电视、机顶盒等等。
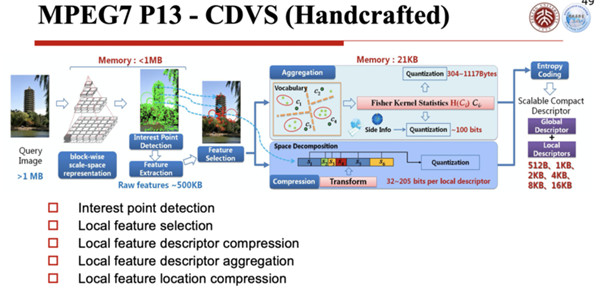
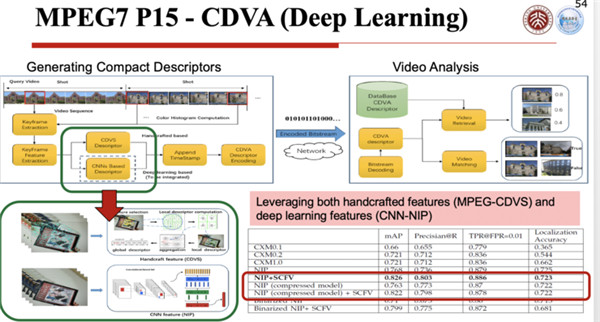
第二个使能技术就是特征编码,这是非常关键的一个使能技术,这个技术里面它的标准有两部分核心的内容,一部分叫CDVS,一部分叫CDVA,这两部分现在也都是国际标准MPEG-7里面的两部分,一个是第13部分,一个是第15部分。
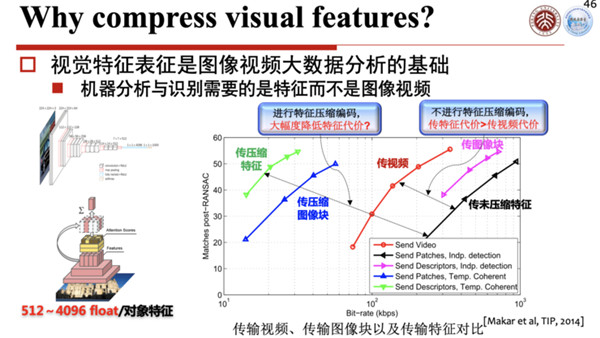
为什么要做视觉特征的压缩呢?因为根据不同的特征,提取出来的特征数据可能很大,如果不压缩的话,搞不好特征数据比图像本身都大,所以要么你就传个图像过去,要传特征的话数据太大,所以就要对它进行特征压缩。
怎么进行压缩?原来有不同的考虑,如果是先把图像编码传过去,再提取特征,再进行识别,和先把特征提取出来,然后把特征传过去再识别,这两个其实有一个剪刀差,可能有时候识别率会先差百分之二三十。
就是说先压缩了以后,可能有一些比较有用的特征丢了,因为所谓编码压缩,它是保留公共部分,把一些非公共的、非常见的东西压缩掉了,而非常见的部分恰恰可能是特征,所以你把这个打磨掉以后,它的识别率可能就下来了,所以我们是先提特征,再在云端技术识别这样一个技术策略。
当然先提特征,怎么样提的特征体量比较小,我们初期是采用手工作业的策略,当然手工特征怎么支持深度学习,这是另外一个问题,后面我们做了第一版以后,又专门做了一个面向深度学习的编码压缩的框架,这个主要是给小视频来做的,有了这两个部分以后,基本上可以应对图像特征编码和视频特征编码这两个需求。
图像特征编码就是CDVS,视频特征编码就是CDVA。CDVS是手工特征的,里面使用的是一个类SIFT的特征集,SIFT大家都知道,当你给的比特数据比较少的时候,它就给一些比较宏观的特征。
基于这样的思路,用这种类SIFT,我们提出了一个特征表达的标准,然后来看它的性能,经过几年的时间,这个性能越提越高,最后把它固定下来。
CDVS实际深是从2012年2月份就开始做,到了2015年6月份就做完了,就完全冻结掉了,最后成为国际标准,所以差不多花了4年的时间把它做出来。
CDVA是在2015年做完以后,标准化组织团队就马上转向利用深度学习去做视频分析特征压缩的问题,也是花了差不多两年多、三年的时间慢慢把它做出来,这个是可以对深度网络的短视频,用它做特征的提取、做表达,后面每次这个特征的性能都会有所提高,对不同的网络,它的特征的检出和特征识别的效率也都在逐步提高,所以每次提高的趋势。
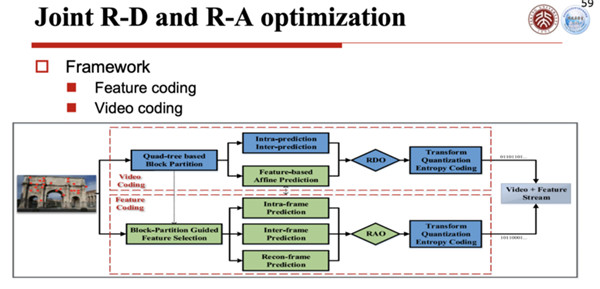
第三个使能技术,我们把它叫做联合优化。所谓联合优化,就是在视频编码和特征编码之间,我要找到一个最优的结合点,使得这两个流捆绑到一起的时候,脑力分配是最优的,上面这个流是视频压缩流,下面这个流是特征压缩流,这样送到云里,它俩合起来是最优的。
怎么能够做到最优呢?因为各自的优化模型都是有的,比如现在我们看到的这些是上面这部分,它是一个视频编码优化的流程,上面的虚线是视频编码,下面的虚线是特征编码,这两个编码在右端,我们是合成一个流,就是视频和特征流。
这一个流我们怎么样优化呢?我们要设置一个联合优化流程,把它放到一起去优化。视频编码的优化模型叫RBO,RBO就是给定码率损失最小的优化模型,它的优化曲线就是右下角这个曲线。在识别特征表达这一块,它是有一个RAO,就是给定码率,让你精确度最高的优化模型。
这个优化模型给的曲线是反过来的,所以我们把这两个需要优化的东西给它放到一个优化函数里面表达出来,就是这张图的表达,根据这个东西我们联合求解一个优化的解,这就是第三个使能技术。
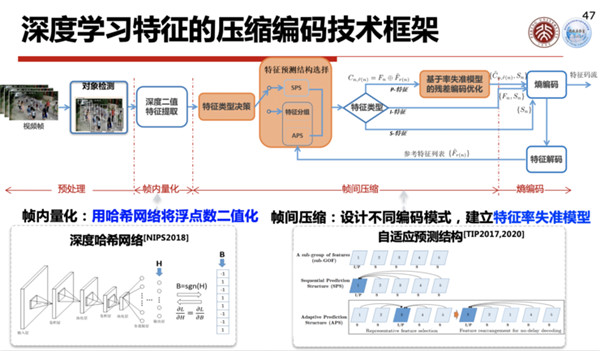
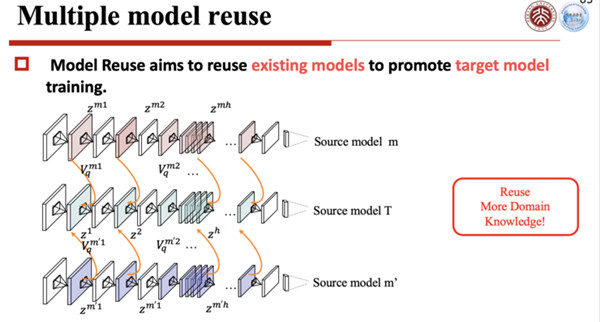
第四个使能技术是深度学习模型编码的使能技术,就是通过多模型的重用,通过模型压缩更新来做。这是深度学习怎么样去通过重用去使得整个模型的重用精度更高。
这个重用既包括现有模型的重复使用,也根据目标模型训练所得到的提升,使得优化做得更好。
这样一个多模型重用,如果是在学习体系里面把它用好的话,它的性能就可以提高得比较好,所以怎么样使得这个多模型编码压缩,使得在重用当中可以快速地更新一个模型,就使得这个性能不停地提升,这两个就是模型编码的主要动机,有了这个就可以使得当你模型训练完了以后,压缩完了以后就可以快速推到终端去升级你的模型。
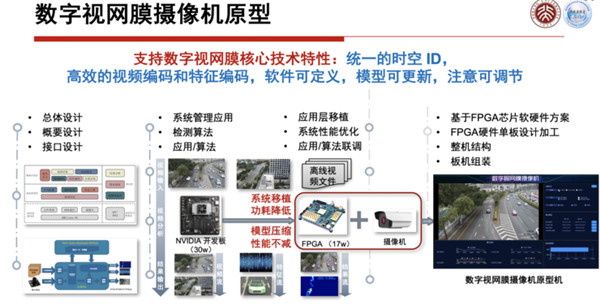
上面这些使能技术,最后它要汇总到一个芯片里面,这个芯片现在在北大杭州研究院下面的一家公司做出来了,第一个数字视网膜的芯片叫GV9531,刚才说的三组8个特性,这个芯片全都是支持的。
这个芯片目前也已经做成了板卡,比如说有4颗芯片的卡、16颗芯片的卡,这些板卡已经可以支持边缘端,一下支持上百路甚至几百路的摄像头数字视网膜特征提取的传输。
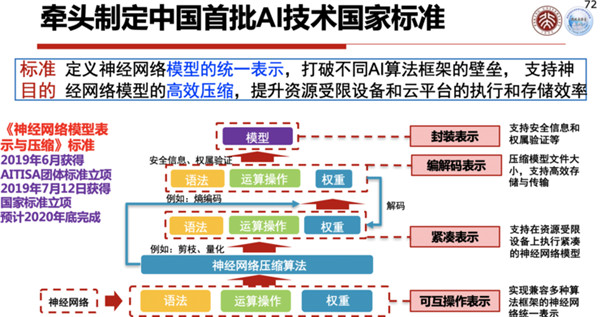
除了数字视网膜本身以外,现在配合人工智能技术的推进,也在推动中国的一些AI技术的国家标准,包括神经网络模型表示与压缩的标准、城市级大数据汇集关联的规范和标准,包括这些标准研究开发的路线图,什么时候要把哪个标准提出来完成等等。
数字视网膜简单来说是三个编码流合并的系统,当然前两个是最主要的,就是视频流和特征流,这两个流时时刻刻都是汇集到一起进行传输的,第三个是模型编码,只是在模型需要压缩的时候,从云端推到边缘端或者终端上,进行一些增量的更新。
有了数字视网膜,就相当于城市大脑边缘或者是终端方面就可以做得更高效,效能比更高,这样就可以使得云端的算力不需要那么多,或者说云端的响应可以更精确、速度更快,这样就使得城市大脑可以做得更好一些。
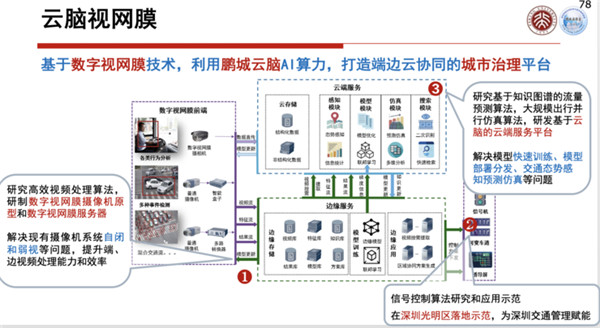
为了配合这个工作,现在城市大脑包括一些中台怎么考虑、业务支撑怎么考虑,应用怎么考虑,现在在鹏城实验室都有一些比较完整的设计和规划。所以整体来说,我们把城市大脑2.0里面的数字视网膜也可以简称为云脑视网膜,这个可以利用鹏城云脑的算力去提升它的能力。
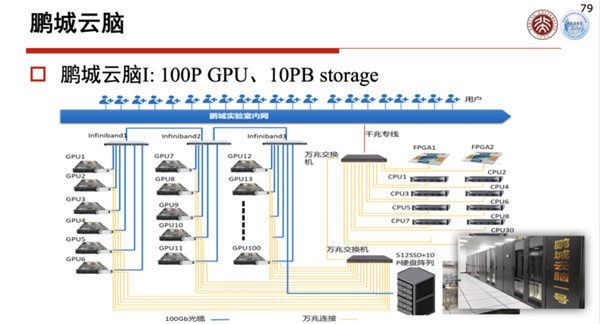
鹏城云脑到现在为止已经投入了几十亿元去打造,鹏城云脑只有100P的算力,虽然说只有100P的算力,这也是到目前为止国内作为AI训练算力最大的一套系统。
后面还会有更强的系统,现在我们有一个原型,可以有数据进来,对数据进行标注、采集,可以进行训练,训练完了以后就可以用刚才这些和芯片有关的系统进行提取,然后可以分析和识别。
这个原型系统,一般的边缘用的,甚至在云端大数据服务里面用的东西,现在都在逐步进入系统,上面会有各种各样的参考软件,去配合硬件的东西,最上面是开源的算法训练,有这些东西之后,将来在鹏城云脑上就会对城市大脑进行比较强有力的支持。
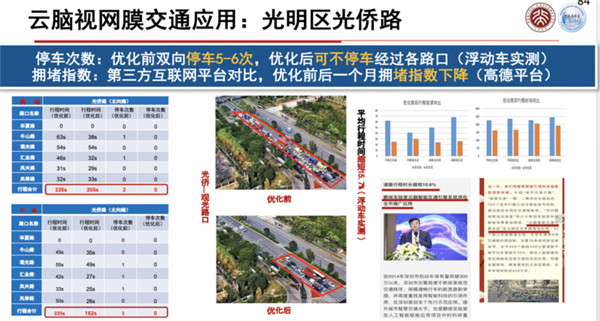
现在已经有一些演示验证的案例,比如说对系统验证,比如说对深圳交警提供的一些数据进行视频的验证,另外还可以进行视频的追踪等等。
在光明区也进行了一些实际验证,对于停车、拥堵等问题都可以很好地分析和发现。
这就是城市大脑2.0到现在为止的一些情况。
总结一下,城市大脑1.0是一个以云计算为核心的系统,由于系统各个部分分工协调不太好,所以系统成本比较高,响应速度慢,数据的可利用度比较低。借鉴人的视觉系统,比如说人的视网膜、视觉通道、大脑分工非常协调,非常合理。
城市大脑2.0就是借鉴这样一个系统提出的一个体系架构,这个体系架构要想把它做出来,需要数字视网膜这样一套思路、技术及其标准化,现在这些思路、技术、标准化都逐步到位。
数字视网膜这套系统上了以后,可以使得现有的城市大脑1.0在编码方面节省50%的存储和带宽,在云资源的耗费上,比现有的可以节省90%以上的云计算的算力资源。
而且它对于图像特征的提取和分析延迟比较低、精度比较高,所以它有很多好处,这是数字视网膜希望带给城市大脑2.0的一个好处。
当然这个系统要想完善,可能还需要一点时间,还需要在更多的地方去做实验验证,等这些技术都成熟了,标准全都到位了,甚至城市大脑2.0真正运营起来,对中国的城市化、智能城市等等方面会有一个比较大的贡献。所以也希望大家多关注、多提比较好的建议和意见。
今天我要讲的内容就是这么多,谢谢大家。


















|

